

Today’s PAAD is a bit longer and more technical than our usual PAADs but please take the time and effort to read it, I think it will be well worth your time and effort. As you know, we review as many articles as we can to help you keep up with the medical literature. One of the hurdles we face in picking the articles is: “are the results and conclusions of an article valid?” Increasingly many published articles use metanalysis and systematic reviews to base their conclusions. I know most of you are clinicians and not research or statistical mavens (experts). I wasn’t sure if you understand these analytic techniques and their shortcomings. So, I asked 2 of the smartest people I know, who really do understand this stuff, Drs. Elliot Krane and Gary Walco, to write a cogent review on this topic to help you better understand these techniques. I am also posting another PAAD tomorrow on the failure of honey to reduce post tonsillectomy pain. As you will see this new paper refutes a previous paper that honey worked that was previously reviewed in the PAAD (https://ronlitman.substack.com/p/copy-a-spoonful-of-honey-may-help ).. Why the difference in results from the same research group? One was a metanalysis the other a randomized controlled trial.. Myron Yaster MD
Does it seem to you that every other paper you’ve read lately is not a primary clinical study, but is a meta-analysis or a systematic review?
Well, in fact there indeed has been a proliferation of systematic reviews and meta-analyses that has eclipsed the number of clinical trials, which have generally declined in number since 2021, as can be seen from this bar chart showing the results of a PubMed search:
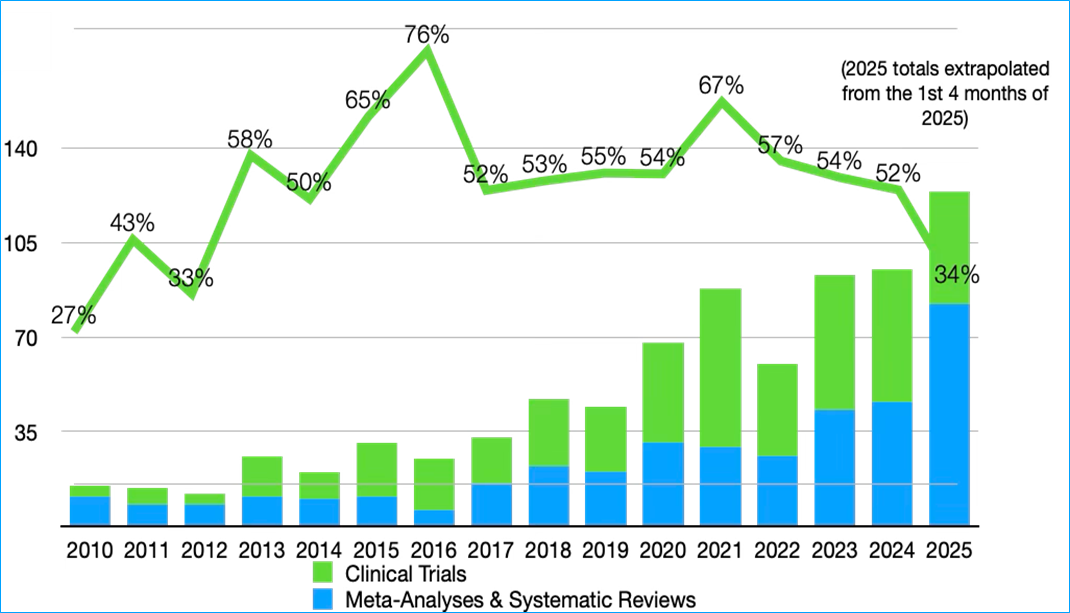
And have you wondered what the difference is between a meta-analysis and a systematic review? ChatGPT provides a cogent definition of these methodologies:
A systematic review is a structured, qualitative review of relevant studies of a particular research question. It follows a clearly defined protocol that includes:
· A focused research question (usually PICO: Population, Intervention, Comparison, Outcome)
· Predefined inclusion/exclusion criteria
· A thorough search of multiple databases
· A critical appraisal of study quality of the identified papers
· And a qualitative synthesis
A meta-analysis is a statistical technique used to combine and analyze the numerical results from multiple studies, following a clearly defined protocol that includes:
· The first 4 bullet points above of a systematic review
· Calculation of a pooled effect size (e.g., odds ratio, mean difference)
The meta-analysis produces
· An increased statistical power and precision compared with a systematic review
· And often forest plots to visualize results
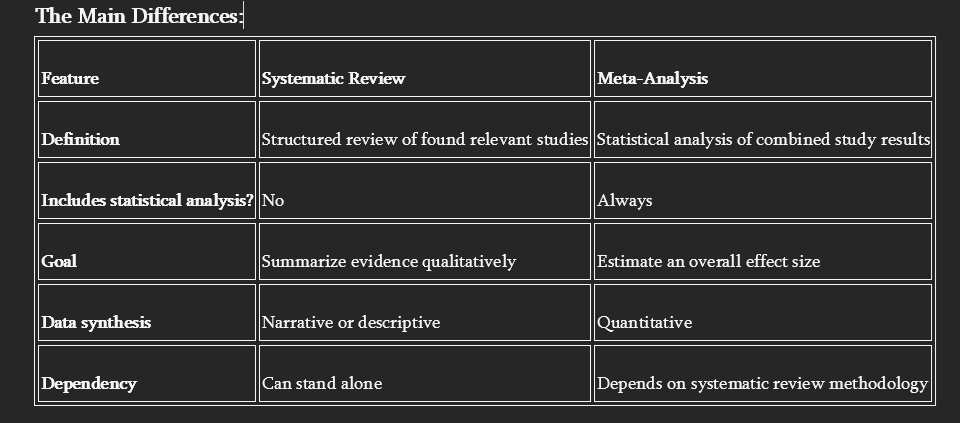
In other words, a systematic review is a descriptive review of the literature, and a meta-analysis builds on the literature search of a systematic review then subjects the papers to well defined statistical analyses to derive a composite statistical conclusion regarding a clinical question.
Why have these derivative review methodologies eclipsed original clinical studies? The answer is simple, it is much easier and cheaper to execute a systematic review or a meta-analysis than to execute clinical studies, thereby generating other incentives as well:
1. Meta-analyses are faster and cheaper to produce
· Clinical trials require extensive planning, funding, regulatory approval, data collection, and patient follow-up.
· Meta-analyses, in contrast, can be conducted from existing published data, often with fewer resources and shorter timelines. All you need is a question, a graduate student, a statistician and a computer.
2. Incentive structures in academia
· Thereby, making success in an academic department more assured: promotion and funding are often tied to publication quantity.
· Meta-analyses, especially the easier to execute systematic reviews, are publishable, count as scholarly output, and can be completed more readily than new clinical trials. (At Stanford it is said, “The Dean can count, but he can’t read” —EK)
3. Increasing availability of data
· The explosion of published research and clinical trial registries has created a large accessible data source for meta-analysts.
· Open-access datasets and standardized trial reporting (e.g., CONSORT) make it easier to aggregate and synthesize findings.
4. Perceived high evidence value
· Meta-analyses (especially of RCTs) sit high in the evidence hierarchy and are often cited in guidelines and policy documents.
· This prestige motivates researchers and journals to favor them.
5. Replication crisis and need for synthesis
· With growing awareness of reproducibility issues, researchers and clinicians increasingly turn to meta-analysis to distill reliable conclusions from varied studies.
6. Journals’ preferences
· Journals often prefer review-based papers that attract broader readership and more higher citations, further incentivizing meta-analytic work.
This surge has led to concerns about redundant or low-quality meta-analyses, especially those that:
· Rehash similar questions without adding value
· Include low-quality or heterogeneous studies
· Lack proper statistical rigor
Many metanalysis papers almost certainly include low-quality and heterogeneous studies, exemplifying the “garbage in, garbage out” phenomenon. To further this point, we would like to draw your attention to 3 important papers that discuss the problem of “garbage in, garbage out.”
The first is a classic paper by Dr. John Ioannidis, an internationally known biostatistician.[1] This paper made a big splash by publishing his depressing analysis showing that upwards of 75% of published clinical studies have inadequate statistics or are just plain wrong. (If this seems improbable, then ask yourself this: Assuming you read one or more papers per week, of the 500+ papers you have read in the last 10 years, how many of them have led to a new advancement or an important alteration in clinical care? If you can list 100, which is 20%, we’ll buy you lunch.) Because no meta-analysis we’ve read has carefully examined the statistical analysis of every included paper, the extrapolation of Ioannidis’s paper is that as much as 75% of their data may be completely wrong, therefore the meta-analysis has a high probability of being wrong.
The second and third papers appeared last month in the journal Pain.2,3 To briefly summarize the Sundström paper,[2] we will quote directly from the editorial of the paper[3] that echoes an example of the Ioannidis principle and is virtually incomprehensible:
“In conclusion, Sundström et al.’s findings corroborate the idea that the group’s average may not represent any of the individuals of that group in these chronic pain samples. Whenever the ergodicity assumption is violated, the critical question concerns the primary aim of the researcher. If the goal is to gather knowledge about people with pain in general, there is nothing wrong with continuing to apply a group-based nomothetic approach. However, understanding individual pain processes and developing personalized pain care requires a new idiographic approach. For the latter, studies adopting single case observational designs or single case experimental designs that focus on the dynamics of different pain measures in one person are more suitable.”
And for those who don’t know the definitions of ergodicity and nomothetic (we didn’t):
Ergodicity: the property that the statistical properties of a single system observed over a long period are equivalent to the statistical properties of many identical systems observed for a shorter period.
Nomothetic: relating to the study or discovery of general scientific laws.
What does this mean? In pain studies of groups of subjects, the statistical outcome of the data will reflect the population, but it will not necessarily reflect the experience of any individual in the population. This must certainly ring true to many of you who practice pain medicine, especially caring for chronic pain: often a treatment has been “proven” to not have efficacy, which is to say, a positive outcome in a randomized clinical trial with well defined parameters (e.g., age/gender/race/past medical history of subjects, environment of patient (e.g. concomitant diagnoses, drug therapy, geography, weather (cold vs hot), etc.), but your experience is that in some individual patients whom you have carefully selected the treatment has been demonstrably effective. Was the literature wrong on that treatment? Are you wrong in using it? The answer to both questions can be “no.” And therefore, you can see the practical limitations of combining the outcomes of many clinical trials into one statistic.
The answer to the conflict between population efficacy studies and individual subject effectiveness is the development of a new approach to pain studies and their statistical analysis, then the delivery of personalized medicine, and it certainly may not be the number crunching of a hundred previous studies to derive a new larger population statistic…unless you are up for promotion. ;-)
We will have more to say about this in upcoming PAADs. Send your thoughts and comments to Myron who will post in a Friday reader response.
References
[1] Ioannidis J. Why Most Published Research Findings Are False. PLoS Medicine 2005; 2(8):696-701.DOI: 10.1371/journal.pmed.0020124
[2] Sundström FTA, Lavefjord A, Buhrman M, McCracken LM. Are People With Chronic Pain More Diverse Than We Think? An Investigation of Ergodicity. Pain 2025; doi.org/10.1097/j.pain.0000000000003573
[3] Vlaeyen JWS, Milde C. The Precarious Use of Group Data to Understand Individual Processes in Pain Science. Pain 2025; doi.org/10.1097/j.pain.0000000000003574